SQL Server Index Mastery: Choosing the Right Column Order
- Eitan Blumin
- May 13, 2024
- 6 min read
Updated: May 22, 2024
Introduction
SQL Server performance optimization is not a simple topic, and index design plays a pivotal role in it, determining the efficiency of database queries.
One key aspect that often influences performance is the order of columns in an index.
In this guide, I'll use my real-world experience from our consulting jobs to examine the thinking process behind selecting the best column sequence for an index, the logic behind the decisions, and offer some practical insights for optimal database performance.
On this page:

Understanding Index Key Column Order Logic
Choosing the order of key columns in an index involves considering how queries interact with the data.
When SQL Server executes a query, it seeks to leverage the index's structure to quickly locate and retrieve the required data. The order of key columns determines the efficiency of this process, depending on the query predicates (filters) that are used.
The preferable order of key columns in an index would normally reflect the order of the operations in a query execution plan, and usually goes like this:
Equality
Range and Inequality
Sorting and Grouping
Output and non-SARGEable

Let's break down the logic for each:
- Equality Columns: These are columns used in WHERE and ON clauses with the "=" operator. Placing them first in the index is generally beneficial as it allows for quick and precise data retrieval. Also, it's generally preferable to place columns filtered by WHERE before columns involved in join predicates (inside the ON clause). Or more specifically, place columns filtered by parameters or scalar values before columns filtered by other columns. Doing so will allow the SQL engine to filter as much data as it can before joining between data sets, making the data sets smaller and faster to join.
- Inequality and Range Columns: Followed by columns involved in range or inequality conditions. If applicable, include columns used in range queries, such as those involving the BETWEEN operator or other comparisons using greater than or less than operators. To implement range filtering, the SQL engine uses leaf-level scans combined with a seek of the starting point, therefore that should be the last thing it does after filtering as much of the data as possible.
- Sorting and Grouping Columns: To optimize queries that involve GROUP BY and/or ORDER BY clauses, it's best to also add the relevant columns as key columns in the index. Logically, those would be applied after any filters such as WHERE clauses, and their placement in the index key columns should reflect that. Specifically for ORDER BY clauses, the order of key columns in the index must be the same as the order of columns in the ORDER BY clause.
- Output and non-SARGEable Columns: Finally, add to the INCLUDE section of the index the columns used in the SELECT clause or those involved in non-SARGEable conditions that cannot be implemented using an index seek (for example WHERE Column1 IN (1,5,459) OR SUBSTRING(Column2, 1, Column3) = Column4). Adding such columns to the INCLUDE list ensures that the index covers all aspects of the query, avoiding additional overhead operators such as Key Lookup and RID Lookup.
Rationale Behind Optimal Key Column Order
Understanding how B+ index seeks work in SQL Server is crucial for determining the best order of key columns. When an index has more than one key column, the database engine tries to efficiently locate and retrieve the desired data.
Seek Predicate: This is the condition applied during the index seek operation. For optimal performance, the leading key columns in the index should align with the columns specified in the equality conditions of the query's WHERE clause. The index seek predicate is instrumental in narrowing down the data set, making subsequent operations more efficient.
Seek Predicate (Multi-Column): When more than one column is being filtered as part of an Index Seek operation, it works as a "nested" B+ tree. In other words, once the seek on the first key column is done (i.e. the requested value is found), "under" that one value you would find another "sub-tree" for the next column in line.
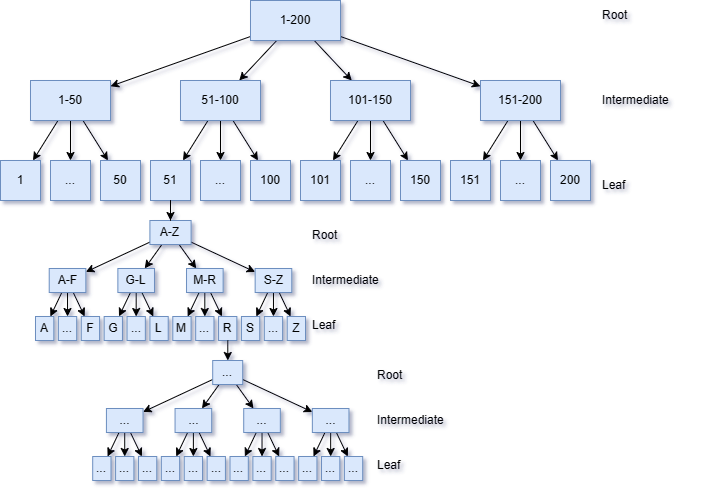
Predicate (Leaf-Level): After the index seek, the leaf-level predicate comes into play. This involves additional conditions, such as inequalities, ranges, or additional filters, applied to the retrieved rows. However, these conditions are evaluated at the leaf level of the index structure. To minimize the impact of the leaf-level predicate, consider the order of columns used in range conditions or inequalities.
Best Practices for Key Column Selection
Okay, so we categorized our index keys into 4 categories... But what if we have multiple columns that fit the same category?
Selectivity: Take into account the selectivity of columns. When a column is considered "highly selective", that means it has a high percentage of distinct (unique) values compared to the total rows in the table. For example, a Primary Key column is at the highest level of selectivity. Such columns are often more effective as the leading key columns. i.e. they should come first.
Please keep in mind, though, that this consideration is only relevant for equality columns (i.e. those used with the "=" operator).
In contrast, columns normally used in Range conditions, such as DateTime, are expected to be highly "selective". However, choosing them as the leading key column for queries that have multi-column predicates is very bad.
T-SQL Examples for Creating Indexes with Proper Column Order
Here are some T-SQL examples to illustrate the creation of indexes with the right column order.
Let's take the following SQL query for which we need to create a most-optimized index:
SELECT a.OutputColumn1, a.OutputColumn2
FROM dbo.YourTable AS a
INNER JOIN dbo.OtherTable AS b ON a.JoinKey = b.JoinKey
WHERE a.SelectiveEqualityColumn = @param1
AND a.LessSelectiveEqualityColumn = @param2
AND a.RangeColumn BETWEEN @from AND @to
ORDER BY a.OrderByColumn ASCThere are a few important things to note here so let's break it down:
The columns SelectiveEqualityColumn and LessSelectiveEqualityColumn are filtered using the equality operator (=).
The column JoinKey is used in the ON clause of the INNER JOIN.
The column RangeColumn is filtered using a range operator (BETWEEN).
The column OrderByColumn is used in an ORDER BY clause.
The columns OutputColumn1 and OutputColumn2 are returned in the output.
For the above query and based on what we discussed earlier, the following index would be most optimal:
-- Example of an index with key column order
CREATE NONCLUSTERED INDEX IX_SampleIndex
ON dbo.YourTable (SelectiveEqualityColumn, LessSelectiveEqualityColumn, JoinKey, RangeColumn, OrderByColumn)
INCLUDE (OutputColumn1, OutputColumn2);In this example, the key column order aligns with the logical sequence discussed earlier. Specifically:
The following are chosen as the index key columns: SelectiveEqualityColumn, LessSelectiveEqualityColumn, JoinKey, RangeColumn, OrderByColumn
The following are chosen as the index include columns: OutputColumn1, OutputColumn2
Common Pitfalls and How to Avoid Them
While optimizing key column order, be mindful of common pitfalls that can hurt performance:
- Overemphasis on a Single Query: Avoid optimizing the key column order for a single, rarely used query at the expense of common queries. Aim for a balance that benefits the majority of query scenarios. Do your best to avoid redundant indexes when one index can benefit multiple query types.
- Neglecting Regular Analysis: Query patterns may evolve over time. Regularly analyze and adjust key column orders to accommodate changes in database usage and development.
- Indexing non-range inequality conditions: Let's consider a couple of examples: What do you think would be the best way to index a subset of data identified by the condition "WHERE StatusID <> 3"? Or how about "WHERE CategoryTypeID NOT IN (5,8,19)"? It's not something that the SQL engine can easily seek using an index on "StatusID" or "CategoryTypeID". However, assuming that this non-range inequality condition is something "constant", well-known, and well-established in business logic (in other words, the same filter is used repeatedly throughout the app workload), you could create a filtered index defined with the same inequality filter. This will create the relevant subset of data for you in advance which your queries will later be able to utilize efficiently. For example: CREATE INDEX IX_Filtered ON MyTable (KeyColumn) WHERE StatusID <> 3
- Indexing non-SARGEable expressions: A non-SARGEable expression, by definition, is an expression that cannot be natively 'translated' by the SQL engine into a "search argument" that could then be utilized in an index seek operation. The two main examples of non-SARGEable expressions include: applying a scalar function on one or more columns (e.g. "ISNUMERIC(MyStringColumn) = 1", or "TRY_CONVERT(date, MyOtherColumn) IS NOT NULL", or "DATEADD(dd, DaysToExpire, CreateDate) < GETDATE()"), and the other example is the use of a wildcard at the start of a LIKE condition (e.g. "ColumnName LIKE '%search'"). You wouldn't be able to create a simple index for such a thing, and filtered indexes do not support the use of functions using columns as parameters. However, there are ways to work around those limitations with the help of computed columns and/or indexed views.
Conclusion
In conclusion, the order of key columns in your indexes is a critical factor in achieving optimal SQL Server performance. By understanding the logic behind column sequencing, following best practices, and avoiding common pitfalls, you can fine-tune your indexes to enhance the efficiency of your database queries. Stay tuned for more blog posts where we'll tackle SQL Server performance optimization.
Additional Tip:
- When in doubt, experiment with different key column orders and monitor query performance to find the optimal configuration for your specific use case. Consider using Hypothetical Indexes to create "simulations" before actually creating an index.
The progression system in Geometry Dash is quite motivating, as players have the opportunity to unlock new icons, colors, and trails by completing various achievements and challenges.